A couple of months ago I set out to investigate some orchestration tools for Docker containers. I.e. something that would help us schedule Docker containers onto nodes in a cluster and make sure that our services stays up in case of various failures. But let’s start at the beginning, why would we need this in the first place?
Prior Setup
We had a somewhat decent setup even before we moved to Kubernetes. For example we were using continuous delivery for every service from Jenkins so that on each commit we would run our tests and integration tests (in Docker), generate an artifact, build a Docker image, push it up to our Docker registry and deploy it to a test server. With a click of a button we could then deploy this (or a previous) image to a production server. Essentially it looked something like this:
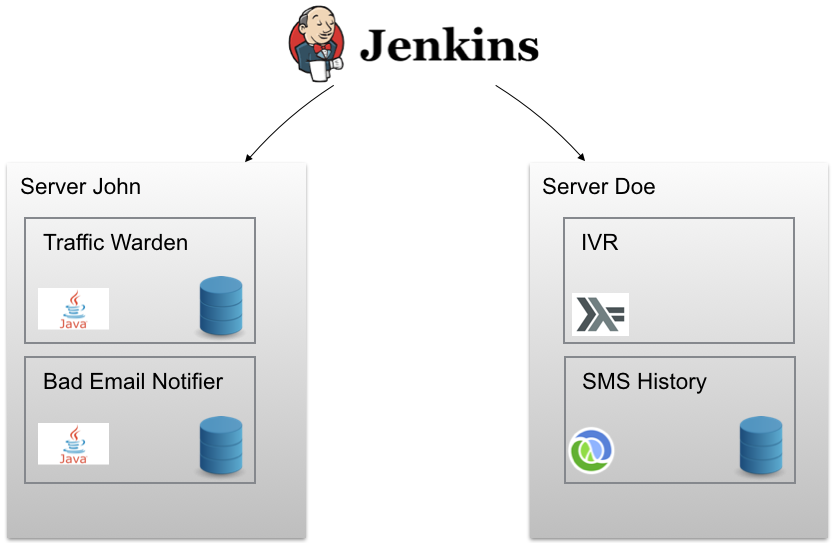
The outer boxes (named John and Doe) contains a set of Docker containers (inner boxes) deployed to this node. We were also using Ansible to provision our nodes. We could, with a single command, create a new cloud server and install the correct version of Docker/Docker-Compose, configure firewall rules, setup unattended upgrades, email notifications, New Relic agent and so on. Each service (running in a Docker container) had upstart scripts that would automatically restart them on failure. But things could go wrong! Just watch this:
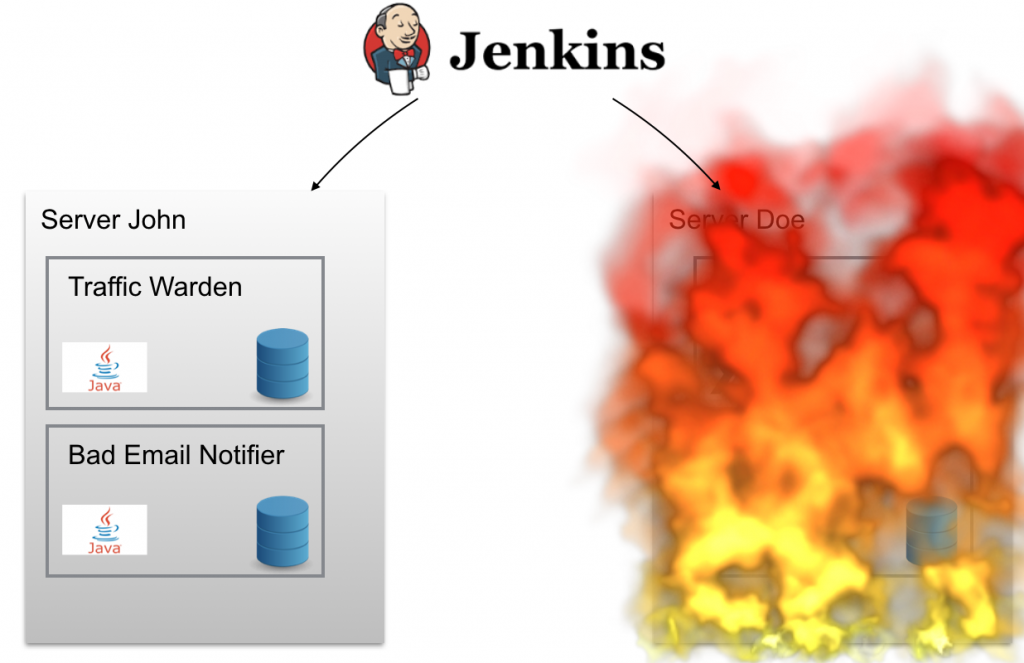
Poor server Doe! If “Doe” went burning in the middle of the night (or just had a temporary outage) we were woken up. The services (docker containers) running on “Doe” were not moved to another node (for example to “John”) so we would have some (partial) downtime of our system. Our servers were like pets to us, we cared deeply about their wellbeing and if one went missing we would be very unhappy. There were other problems as well. How many Docker containers can we fit onto one node? How about service discovery? Rolling updates? Aggregated logging? We needed something to help us out. Something like this:
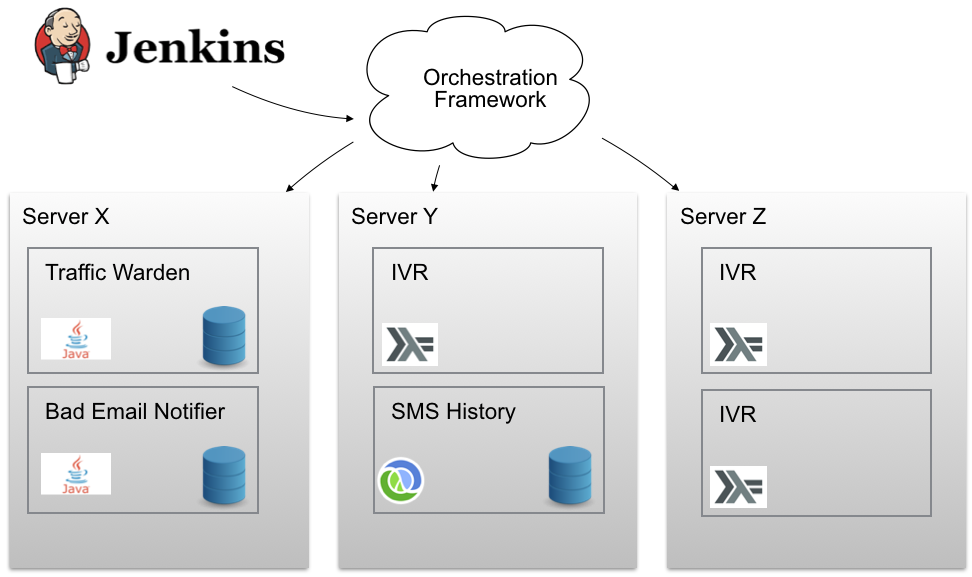
We would like our magic orchestration framework to help us distribute our containers in a cluster of nodes. We want to view multiple nodes as just a single one and tell it “Hey there Mr Magic Orchestration Framework, would you mind deploying 3 instances of this Docker container somewhere in the cluster and make sure it’s up and running despite of failure? Thank you!”. Now all we had to do was finding such a framework.
Wish List
This field is moving extremely fast even by the normal standards of software development and there’s a lot of vendors and competition. We wanted something that is as stable as it gets and likely to be around and maintained for a while. We also wanted something that was easy for us to get started with. For example it would be great if the framework would use something similar to docker-compose which we were already using so that we don’t have to redo a lot of configuration and setup. But we would also like the framework to be simple in the Rich Hickey sense. The framework should preferably not contain too much magic that may leave us without control. It would be great if it was somewhat modular so that certain parts could be replaced if required. An open source framework would also be nice since it would allow us to keep an eye on the progress of the project and report issues etc. Also if the current backer(s) bail out someone else might continue working on the project. It would also be of interest if the framework provided multi-cloud capabilities. Both in the sense that it would be able to get it up and running on various different cloud provides to avoid lock-in but also to potentially schedule containers to different clouds (if configured to do so). Another thing we suffered from previously was service discovery. Thus we wanted it to be easy to reach out to other internal services in our cluster without changing the application code. And lastly we would prefer a managed “framework as a service” option so that we can keep the hassle of setting up and maintaining it to a minimum.
Finding a Framework
I set out to investigate a couple of different alternatives that I found interesting and these were the ones I looked into:
Note that I did most of my research in October/November of 2015 so things might not be 100% accurate today.
AWS ECS
AWS ECS Container Service is a highly scalable, fast, container management service that makes it easy to run, stop, and manage Docker containers on a cluster of Amazon EC2 instances. If you’re already on AWS it would be outrageous not to look into this service. We were not on AWS but had no trouble moving there if ECS would turn out to be a good fit. Running on AWS is indeed very tempting. It’s an awesome and mature cloud provider and with it you get access to all of AWS infrastructure and services. ECS also distributes the containers across multiple availability zones automagically which is great for availability. It’s also a managed service by Amazon which is what we were looking for. But everything was not just fun and games. I had actually experimented with ECS before it was publicly released and the experience back then was not the smoothest (but since it was just in beta back then this was to be expected of course). So I wanted to give it another go. I started reading the docs and compared it to some of the other alternatives and to me it still looked quite complicated to get started with. The getting started guide just seemed a bit long and involved things like IAM policies and security groups. While this can actually be a good thing it’s an additional step before I can actually try things out for real. So I started googling a bit first and I soon discovered that there was no built-in support for service discovery. This is a huge downside since you would have to manage and configure that yourself. Another things was port management. It didn’t seem to me that you would be able to run multiple containers exposing the same port on the same node. These things led me to at least look elsewhere to see how to competition would stack up. (Later I found this excellent blog which confirmed my thoughts).
Docker Swarm
Docker Swarm is the native clustering for option Docker. Because Docker Swarm serves the standard Docker API, any tool that already communicates with a Docker daemon can use Swarm to transparently scale to multiple hosts. The latter sounded really great (easy) for us since we were already using `docker-compose` to start our services. It also meant that we didn’t need to learn much new. We already knew Docker and Swarm uses the standard Docker APIs. But by the time we looked into Docker Swarm it had not yet reached 1.0. This was the main reason for not picking Docker Swarm. But there were other things as well that were a bit tedious. For example while Swarm supports a wide variety of service discovery engines I heard from an ex-colleague that setting this up, and more importantly having it stay up, could be a bit of a hassle. I.e. Docker Swarm is not a managed service so we would have to make sure that it’s working and is up and running by ourselves. Rolling updates didn’t turn out to be as easy as in some of the other alternatives we tried. At least back then, doing a rolling update of containers in Swarm was something that you had to implement yourself. For example by setting up Nginx as a load balancer infront of a group of containers. At this time there was also some worries that the design of Swarm might be flawed. For example in this stackoverflow answer a Google Engineer expressed some concerns that:
Fundamentally, our experience at Google and elsewhere indicates that the node API is insufficient for a cluster API
Mesosphere DCOS

After having started DCOS (datacenter operating system) on AWS using a cloud formation template and logging in to the UI you notice how nice it is. You get a good overview of the cluster including which services are running, CPU and memory consumption. DCOS can run on any cloud and also work across many clouds while up an running (I haven’t tested this since it requires the enterprise version). It builds on Mesos which is known and battle proven on large scale clusters. DCOS also has a lot of features. It not only run Docker containers, you can also run stand-alone apps (such as Ruby) along side the containers. It has an internal event bus that captures all API requests and scaling events that can be used for load balancing etc. It also has metrics support with built-in with support for graphite and data dog (and it uses the codehale metrics format). Other things such as cluster auto-scaling is also included (and here it uses the host cloud’s autoscaling capabilities to achieve this). And there are tons more! What’s super interesting with DCOS is that you can actually run several frameworks at the same time in the same cluster. This means that you can run both Marathon, Kubernetes, Docker Swarm side by side! On the security side they provide three different so called “security zones”: admin, private and public which allows deploying your apps into various layers of security. For example the “private” zone is not reachable from the internet. Another really cool feature is the ability to install services by a simple command: dcos install ... You can think of it as an apt-get for your datacenter. You will be able to install a highly available HDFS cluster in minutes and other services such as Cassandra, Spark, Storm, CrateDB etc are also available. Service discovery is typically handled by a HAProxy instance whose config is reloaded automatically when new services come and go. It supports rolling updates for applications (they are called “rolling restarts” in DCOS) and they should work without downtime (I didn’t actually test this). Last but not least they support a project called Chronos which allows for running distributed tasks in the cluster (like distributed cron jobs). I was really excited to try out Mesosphere DCOS but unfortunately it has its set of caveats as well. Although not exactly a caveat, only the enterprise version supports the multi-cloud capabilities (which is reasonable). Also it’s not a managed service. It’s easy to spin up a cluster on AWS but then you’re own your own if you’re using the free version (which to be fair is also reasonable). But a letdown for me was that I actually tried to get in contact (by email) with Mesosphere to ask for the price of the enterprise version but they never replied. Being a startup its quite likely that we wouldn’t have afforded it anyways but it would be nice to know for sure. And while `dcos install` is simply awesome the set of services they provide that are not in alpha or beta (and thus not recommended for production use) is limited to Marathon or Chronos (which also has its set of flaws). Another thing that concerned us was how we could upgrade the cluster without downtime. Reading the docs at the time just said that one should make use of ETL.. Eh ok, thanks? If we don’t host any stateful services in the cluster an upgrade would probably be quite easy (spin up a new version ofDCOS behind and switch the ELB to point to the new cluster once it’s up) but one of the nice things with DCOS is the ability to host stateful services such as hdfs, hadoop etc. If we can’t upgrade the cluster to a new version in an easy manner “without downtime” we will not be able to keep up with the latest releases. I jumped on slack to discuss this and the answer was that they are working on it. Unfortunately this was not a satisfactory answer for us right now 🙁
I actually felt a bit sorry that we came to the conclusion that Mesosphere DCOS was not be the best fit for us right now. In a few years(?) when the services and frameworks have been hardened and battle tested a bit more DOCS is going to be awesome! But imho they’re not quite there just yet (at least not at the time we looked at it).
Tutum
Tutum describe itself as “The Docker Platform for Dev and Ops”. Its tagline is “build, deploy, and manage your apps across any cloud” and the UI looks like this:

While not quite as good looking a DCOS (imho) it’s still great and you can do almost anything Tutum provides by using the UI (which is great when getting to know a new product but can be deceitful in the long run since it may prevent one from a declarative environment. Tutum has great CLI support as well btw). In order to use Tutum you install the tutum agent on each node you want to participate in the cluster (which is very easy). The node then pops up in the UI and you can start using it. What was particularly interesting for us with Tutum was that they were using a `docker-compose`-like format for declaring stacks (consisting of multiple services/containers). This means that it would be less things for us to change. They also had great support for volumes by integrating Flocker in the cluster. We did several tests (killing stateful containers) and they were restarted (sometimes on different nodes) with the state intact. I was truly impressed by this. Another goodie was service links which allowed us to create links between containers so that some containers are only exposed to other members of a group. If I’m not mistaken this worked even though the containers were hosted on different nodes. For load balancing Tutum made use of HAProxy. It supports virtual hosts so you could deploy multiple services behind the same HAProxy instance. It was also really easy to expose such a load balancer to the internet. When deploying a “service” Tutum offered the ability to distribute multiple instances in various different ways such as High Availability, and “Every Node”. “Every Node” is particularly interesting if you need to run some sort of a daemon or want to guarantee that a service exists on every node in the cluster. They also had a 1-click Docker version upgrade in the cluster. I.e. with a click of a button the Docker Engine was upgraded throughout the cluster which is great. At last I must say that they provided awesome support! Even though we were not paying customers they replied swiftly to our questions and provided great feedback. Shortly after we looked into Tutum it was purchased by Docker so it’s going to be a core part of the offerings. But as with most other things Tutum was not perfect. First of all it was still in beta and pricing was unknown (today the price has been revealed to be 15 USD/node). This made it hard for us to know if we would actually afford to use Tutum when it came out of beta. But the thing that turned out to be the real showstopper for us was that when we (deliberately) made a node completely unavailable (100% CPU and we couldn’t even access the machine using SSH) the containers on this node was not rescheduled on another available node. I talked to support about this and they said the they were aware of the problem and answered that they were working on it. Unfortunately we’ve had experienced exactly this in production so this was really important for us. I also asked for “resource limits” which might have prevented a node from getting completely unavailable in the first place but this was also not yet implemented at the time.
We were really close to picking Tutum but because of the scheduler’s inability to move containers to another node when it became unavailable we couldn’t do so. We had to look elsewhere..
Kubernetes
Kubernetes describes itself as a way to “manage a cluster of Linux containers as a single system to accelerate Dev and simplify Ops”. Kubernetes is open source and is mainly backed by Google but other companies such as Red Hat, Microsoft, SaltStack, Docker, CoreOS, Mesosphere, IBM also collaborates on the project. What’s so nice about Kubernetes is that it brings a decade of Google’s experience of building and running clusters essentially for free. You can run Kubernetes on bare metal or on any cloud provider (they provide for example cloud formation templates for AWS etc). But Google also offers the Google Container Engine service that provides a managed version of Kubernetes. So we decided to give Kubernetes a spin in Google Container Engine. Although not as easy to get started with as for example Tutum (mainly due to the lack of UI features) it felt quite solid once we had understood the concepts. At the time Kubernetes was 1.0 (now 1.1) and was considered production read. We did a lot of tests, for example killing nodes in the middle of a rolling update, killing containers (~pods) randomly, scaling number of containers beyond what the cluster could handle etc. And while everything didn’t work perfectly, at least we could find a way to workaround all of the problems we encountered. Another huge plus was the ability to perform rolling upgrades of the entire cluster without downtime (if state is outside of the cluster at least). And it worked very well in our tests! Service discovery was another thing that just worked in Kubernetes. We’ve never experienced any issues what so ever with its service discovery mechanism. Just connect to the name of a service (`http://my-service`) in your cluster and Kubernetes will make sure you reach the pod behind the service. Kubernetes is also designed to be modular and extensible so that its components can be easily swappable. It also has a lot of features, for example resource limits, volume claims, secrets, service accounts etc. Another cool feature of Kubernetes is that it supports both Docker and Rocket containers (although to be honest I doubt that the support for Rocket is on par with Docker). But Kubernetes obviously has its downsides as well. When running it in Google Container Engine you’re currently limited to a single datacenter. If this datacenter goes unavailable things are not good. Yes, workarounds do exists (multiple clusters behind a load balancer) but it’s not supported natively. But I’ve actually discussed this with some Google Engineers and if I’ve understood it correctly a lightweight form of Ubernetes will appear in 1.2 that will allow for multi-datacenter clusters. Kubernetes has it’s own yaml format for declaring pods, services and other resources which meant that we had to port our `docker-compose` files. Compared to Mesos, Kubernetes is not as mature and does not cope with as many nodes as Mesos does. As of now Kubernetes says it works with clusters with up to 250 nodes (which should be enough for most) whereas Mesos can support clusters with more than 10000 nodes. The Kubernetes UI also leaves much to ask for compared to Tutum and Mesosphere DCOS.
Conclusion
So in the end we settled for.. *drum roll* Kubernetes. It was the most robust solution we tried (we only tried it on Google Container Engine) and we’re confident that it’ll support us as we grow in the future. This is not to say that the other services are bad. As I said earlier this field is moving fast and some of the things I say here might already be out of date. I for one will be following the development of Mesosphere DCOS closely as it looks really promising. But so far we’ve been quite happy with Kubernetes and we’ve been using it in production for a couple of months now. But it’s not without its set of caveats so in a future blog post I’ll be sharing more on what issues we’ve ran into so far and how we’ve managed to work around them.

23 thoughts on “Why We Chose Kubernetes”
Have you look at openshift?
Unfortunately I’ve not yet had the opportunity to look into openshift.
Have a look at Rancher and RancherOS (that said it works perfect on any linux with docker engine).
Unfortunately I haven’t had the chance to look into Rancher/OS much.
I’d +1 Rancher. You can even use it to create a Kubernetes layer (similar to DCOS) that uses the Rancher networking. What this gives you is Ubernetes benefits, already solved.
Not to mention it’s much easier to set up on AWS since Rancher itself is a container.
+1 on Rancher as well. It’s hands down the best framework at the moment in terms of flexibility, security, maintenance… you name it. Kubernetes can run on it too.
Agree, this is all we use. It is amazing and knowing the leader behind it and what they accomplished in Citrix land, that experience has shown on this platform. PID 1 is a docker container….amazing.
Nice write-up. Very useful overview and explanation of the various aspects of each.
Is there a reason you didn’t consider Cloud Foundry in your evaluation?
I’m curious if it was previously eliminated for some reason, or if it didn’t even come up in your competitive research. It seems like it would tick off most of your original requirements:
– Stable and mature
– Open Source
– Multiple backers and contributors
– Supports Docker
– Competing options for “CF as a Service”
– Multi-cloud, provisioning “apps” across servers, etc.
Might be something worth considering in the future!
FD: I work on the CF team 🙂
There was no particular reason other than time constraints. I’ve never tried CF but I’ve read and heard about it and it seems interesting as well. Maybe next time 🙂
Great read! Next time, please you paragraphs 😉
Johan, I’ve very happy to see such a rigorous study and to see that k8s came out on top (although I’m hardly unbiased : ).
Can you say more about “while everything didn’t work perfectly, at least we could find a way to workaround all of the problems we encountered”? We’d love to hear what didn’t work and what you had to do to work around it. Thanks!
I’ll try to get a new blog post out today describing this.
A concise table would have been nice.
If you are looking for an alternative to docker-compose, check out @openshift’s Source-to-image (s2i) is a tool for building reproducible Docker images. s2i produces ready-to-run images by injecting source code into a Docker image and assembling a new Docker image which incorporates the builder image and built source. The result is then ready to use with docker run. s2i supports incremental builds which re-use previously downloaded dependencies, previously built artifacts, etc.
more here: https://github.com/openshift/source-to-image
Good read.. I often time think if one can explain a somewhat complicated technique in a very simple intuitive way that even 1st graders can understand, then he/she really thinks things through and understands the gist of it.
However, as mentioned by previous comments, a list of criterias as how you view that one should consider as the most important implementation aspects should be helpful to guide the whole read; as we all know technology moves fast but fundamentals do not change much……
Nice comparison. We also chose Kubernetes for managing our IoT platform (https://www.cloudthing.io), and my cofounder explains why here: https://blog.husarlabs.com/why-we-chose-kubernetes-for-cloud-platform-management-33b4aa394bb7#.k83mgd8p4
Great post! could anyone provide realworld experience update on DCOS (Mesos), I am more and more interested in this platform. We are in the moment using vSphere and CentOS with help of Puppet & Ansible. We have in total around <100 servers, so not as big as others here, but it is already something which sometimes is not easy to manage 🙂 We use puppet/ansible, etc.
Now we go with new hardware (up to 16 cpus per server – IO cards), we will stay still with vSphere as top hypervisor, we plan now to have bigger VMs then before and with help of Docker to run multiple app on one VM(20 cpu cores and 20GB memory for example). Previously we had one VM per project/app/database, now we will have bigger VMs for shared resources. DCOS looks like good candidate, so I welcome any positive/negative up-to-date experience ladislav dot jech at coreso dot eu